

AIやSEOに強いHTMLコーディング
AIO/SEO FRIENDLY検索エンジンやAIはサイトに記載されているコンテンツを読み取り、利用者のニーズによりマッチするサイトを紹介しますが、その助けとなるのが、HTMLコーディングにおける「AIO・SEO」対策です。
弊社が行っている「AIやSEOに強いHTMLコーディング」を作るためのノウハウの一部をご紹介いたします。
- 1
セマンティックコーディング
セマンティックとは、ウェブの情報を、コンピューター自身が理解しやすいように、HTMLタグに意味を持たせることです。HTML5では、HTMLタグを本来の定義づけに利用するため、いくつかのタグ定義が追加されました。header,footer,nav,article,aside 等がその一例です。
過去のHTMLとの後方互換性も残しつつ、データ量が増えている現状のインターネットにおいて、意味づけに重点を置いた定義を行い、コンピュータの理解できるインターネットを作ろうというメッセージが含まれているのではないかと思います。
弊社ではこのHTML5で導入されたHTMLタグを利用して文章の意味/構造を明確にし、しかしながら表現の自由度は損なわないようCSSやJavaScriptを用いてWebページを実装する「セマンティックコーディング」を基本としております。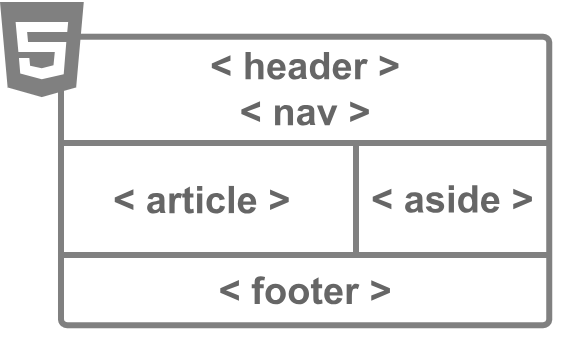
検索エンジンが読み取りやすいコード

SEMで重要となるターゲットキーワードに合致しやすい最適なマークアップ
セマンティックコーディングされたHTMLの「わかりやすさ」は、例えばCSSや画像表示を無効化すると一目瞭然です。
Webサイトが見出し、小見出し、本文とその付録、といった形で定義されていることがわかります。見た目の装飾は一切ありませんが、文章自体を理解するには逆に読みやすいと思われないでしょうか?実際、検索エンジンはこの状態のWebページを見ています。ここから見出しや要約文、ナビゲーション情報などを抜き出して検索結果に表示をしているわけです。 - 2
構造化データ
HTML5によるセマンティックコーディングの導入により、検索エンジンは今まで以上にサイトコンテンツを知ることができるようになりました。しかしながらまだ完全とは言えません。HTMLを用いて個々の文や節に意味づけをすることはできますが、ページ全体を要約し、何のトピックについて書かれているかを明らかにすることは困難です。そこで考え出されたのが構造化データです。
以前よりmetaタグというものがありましたが、metaというのは、その情報に関する補足情報を意味します。これを用いて、例えばFacebookでシェアされたときの画像はこれにする、このページの作者は誰々である等の、Webページに対する補足情報を追加しようというのが構造化データです。この付加情報を、metaタグやmicrodata、JSON-LDといったHTMLタグの派生形式で記述することで、より細かな定義づけができるようになりました。その中でももっとも有名なフォーマットが、Google、Microsoft、Yahooの3社が共同で提供しているScheme.orgという構造化データなります。


構造化データが複雑になるにつれて、
セクションや大括弧や中括弧は増えていく構造化データは予め定義された「vocabulary 」を用いて、ページ内の情報をカテゴライズすることができます。vocabulary の定義は一律で行われているため、検索エンジンは構造化タグを通じてページをまとめ上げる(マッシュアップ)することができるようになります。弊社では構造化タグの設定を推奨しております。多種多様なvocabulary の中から、お客様のサイトに合う構造化タグを選んで実装をいたします。
- 3
コアウェブバイタル対策
サイトの表示速度が遅ければ、ユーザは確実に離脱します。以前はサーバやインターネット回線といったインフラの影響が大きくありましたが、現代では単にサーバやインターネット回線の速度を早くするだけでは、早いとはいえません。Googleはコアウェブバイタルという指標を用いてサイトの速度指標を評価していますが、HTMLコーディングや、CSSの構造、JavaScriptの処理方法を最適化しなければ、良い評価を得ることはできません。弊社では制作時のページスピード確認や、既存サイトのコアウェブバイタル対策を行っています。
※WordpressやCMS実装を行う場合、コアウェブバイタル対策を行うことで運用方法が変わるため、ご指示いただいた場合のみ対応としております。PageSpeed Insightsで表示速度を評価
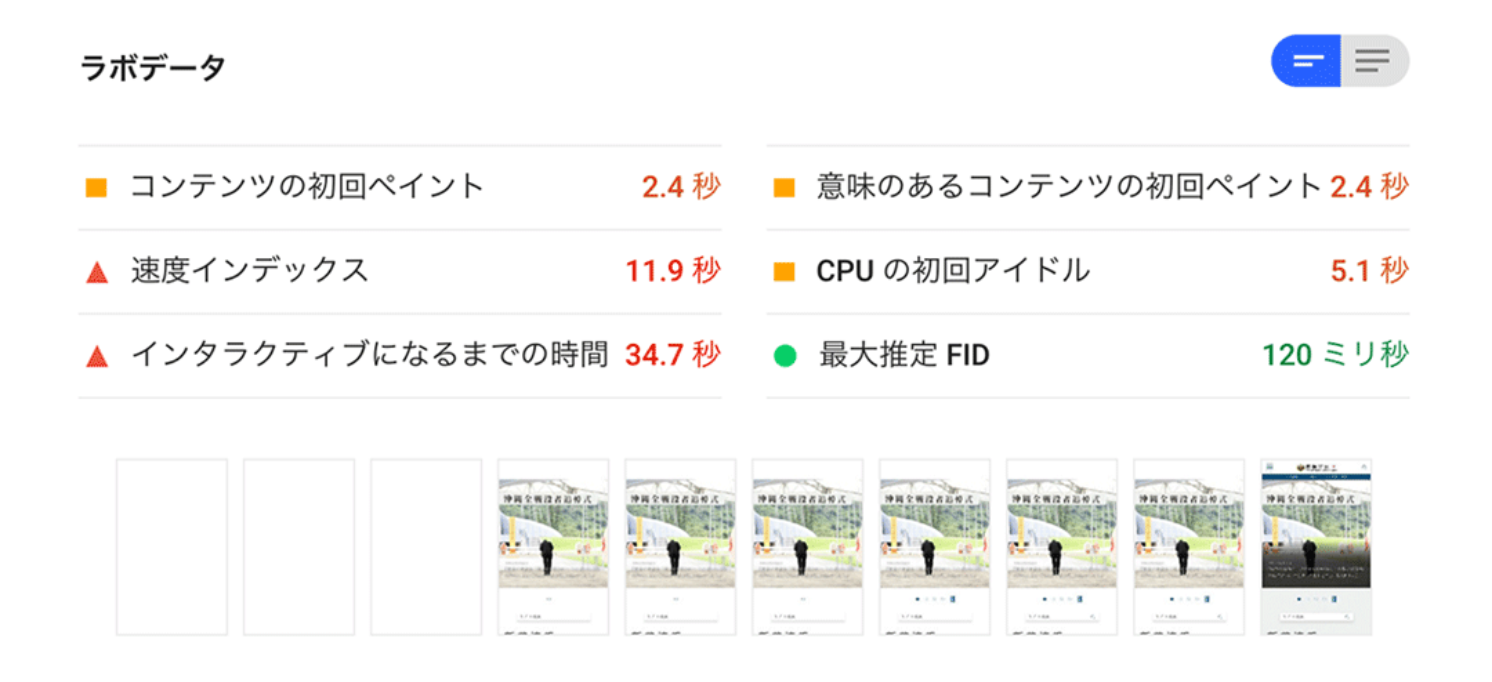
- 01
コーポレートサイト(15ページ)
プロジェクト内容レスポンシブサイト(ブレイクポイント1つ)、WordPress、標準ブラウザ保証、修正無制限
お見積もり料金- 通常サイト基本料金¥ 0
- レスポンシブコーディング¥13,000 × 15P¥195,000
- スライドショー¥ 0
- WordPress(10P以上無料)¥ 0
¥195,000 (税別) - 02
キャンペーンサイト(22ページ)
プロジェクト内容レスポンシブサイト(ブレイクポイント1つ)、簡易スクロールアニメーション、標準ブラウザ保証、修正無制限
お見積もり料金- 通常サイト基本料金¥ 0
- レスポンシブコーディング¥10,000 × 22P¥220,000
- スライドショー¥ 0
- 簡易スクロールアニメーション¥ 0
¥220,000 (税別) - 03
採用サイト(32ページ)
プロジェクト内容レスポンシブサイト(ブレイクポイント1つ)、スクロールアニメーション、標準ブラウザ保証、修正無制限
お見積もり料金- 通常サイト基本料金¥ 0
- レスポンシブコーディング¥10,000 × 32P¥320,000
- スライドショー¥ 0
- スクロールアニメーション¥ 40,000
¥360,000 (税別) - 04
ECサイト(スマホコーディングのみ 300ページ)
プロジェクト内容スマホサイト、流し込みあり、モーダルあり、標準ブラウザ保証、修正無制限
お見積もり料金- 通常サイト基本料金¥ 0
- スマホコーディング¥5,000 × 50P¥250,000
- 流し込みコーディング¥2,500 × 250P¥625,000
- 写真モーダル¥ 0
¥875,000 (税別)
※御用件やスケジュールによっては、異なる御見積になる場合もございます。